-
[칼만 필터는 어려워] 05. 칼만 필터 추정 단계항법연구실/칼만필터 2026. 3. 9. 19:03
* 칼만필터는 어렵지 않아(지은이 김성필) 책을 보고 학습한 내용을 정리한 글입니다.
칼만 필터를 한마디로 정의해보자면, 불확실한 정보들 속에서 수학적으로 가장 믿을 만한 최적의 결론을 계산하는 필터라고 할 수 있다. 칼만 필터는 시스템 모델이 예측한 값과 센서가 측정한 값 중 어떤 것을 더 믿을지 실시간으로 고민하여 가중치를 결정한다. 예측은 이전 기록에서 도출되는 결과이고, 측정은 센서에 찍힌 관찰되는 값이다. 그리고 이 가중치를 통해 최종 결과물인 추정치를 계산한다.
이번 챕터에서는 추정 과정을 이해해보자. 1차 저주파 통과 필터를 배울 때, 칼만 필터의 추정 과정에서 LPF개념이 사용된다는 정보는 이미 말한 바 있다.(저자가 말한 사실을 정리한 것이지만) 칼만 필터에서 추정 식을 생각해봤을 때, 이게 어떤 상관이 있나 싶다. 그러나 식을 전개해서 조금만 바꿔주면 금방 이해할 수 있을 것이다.
칼만 필터 추정값 계산식과 1차 LPF 비교

칼만 필터 추정값을 다시 살펴보자. 앞선 식을 풀어서 작성해보면, 3장을 학습할 때 많이 보이던 식이 나온다.
H가 단위행렬이라고 가정할 때, 이 값은 더욱 명확해진다.

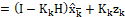
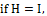
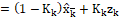
비교를 위해 1차 저주파 통과 필터를 가져와보자,

그럼 비슷한 점이 한 눈에 보인다. LPF에서 α는 정해주는 값이었지만 칼만 필터 추정과정에서 α(=1-K)는 K, 칼만 이득에 따라 다른 값을 가지게 된다. 가중치 역할을 하는 칼만 이득에 대해 자세히 알아보자.
가중치의 변화
앞선 내용으로는 칼만 필터 추정값 계산식과 1차 LPF는 유사하다는 내용을 다루었다. 그럼, 차이점이 무엇인가?를 생각해보았을 때는 어떨까 ? 우리가 다룬 칼만 필터 추정값 계산식에서는 식의 간결성을 위해 H가 단위행렬(주 대각선이 모두 1이고 나머지가 0인 행렬)이라고 정의했다. 또한, LPF에서 가중치 α는 알고리즘 밖에서 고정된 값이었다. 그러나 실제에서 H가 단위행렬이라는 것은 적용이 되지 않는다. 물론 H가 단위행렬이라는 가정이 없어도 칼만 필터의 추정값 계산 식은 LPF와 매우 유사하다.
그럼 가장 큰 차이는 LPF에서 가중치 α는 고정되어 있는 반면, 칼만 필터의 가중치는 변한다. 칼만 필터 추정값 계산식을 다시 보자, 여기서 어떤 값이 변한다는 것일까?
우선 예측값과 측정값은 전달 받는 값이다. H는 시스템 모델으로 칼만 필터 설계 전에 결정되는 값이다. 그럼 남은 변수는 K_k, 칼만 이득이라 불리는 변수 뿐이다. 이 K_k를 알면 새로운 추정값을 계산할 수 있다. 앞서 칼만 필터 알고리즘의 2번째 단계 식을 보자 - 칼만 이득 K_k를 구하는 식이다.

칼만 필터는 알고리즘을 반복하며 오차 공분산 예측값과 일정한 공식에 따라 매번 다른 칼만 이득값을 새로 계산한다. 추정값 계산식의 가중치가 계속 바뀌는 것이다.
오차 공분산 계산
추정의 마지막 단계인 오차 공분산 계산에 대해 알아보자. 사실 오차 공분산 계산 과정은 크게 어렵지 않다.
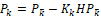
이 공식대로 오차 공분산을 계산해 다음 예측 과정으로 전달하면 된다. 중요한 것은 계산 과정이 아닌 오차 공분산의 의미와 어떤 일을 하는지를 아는 것이다. 오차 공분산은 칼만 필터의 추정값과 실제 참값의 차이를 나타내는 지표이다. 오차 공분산이 크면 추정 오차가 크고, 반대로 오차 공분산이 작으면 추정 오차가 작다는 것을 의미한다. 그래서 칼만 필터의 결과로 나온 추정값을 사용할지 말지를 결정하기 위해 함께 계산하고 출력으로 내보내는 경우도 있는 것이다.
오차 공분산의 의미를 수식으로 알아보자. 실제 참 값, 추정값, 오차 공분산 사이의 관계는 다음과 같이 나타낼 수 있다.

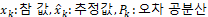
해당 식은 추정값이 평균이고 오차 공분산이 공분산인 정규분포를 따른다는 의미이다. 정규분포는 x_k가 가질 수 있는 값을 확률로 나타낸다. 그리고 이 확률은 평균을 기준으로 대칭의 종모양을 이룬다.

오차공분산 P가 크면 오차 범위가 넓어지므로 넓게 퍼진 종모양이 되고, 반대로 오차공분산 P가 작으면 오차 범위가 작아지므로 좁게 모인 종모양이된다.
오차 공분산의 수학적 정의를 살펴보고 마무리해보자.

E{}는 중괄호 안에 있는 수식의 평균을 구하는 연산자이다. x_k는 참값, hat(x_k)는 추정값을 의미하므로 괄호 안의 값은 참 값과 추정값의 차이, 즉 추정 오차를 의미한다. 오차 공분산 P는 추정 오차의 제곱을 평균한 값을 의미한다. 분산이 편차의 제곱의 평균이므로 해당 개념을 따라간다고 볼 수 있다.
'항법연구실 > 칼만필터' 카테고리의 다른 글
[칼만 필터는 어려워] 07. 칼만 필터 시스템 모델 (0) 2026.03.10 [칼만 필터는 어려워] 06. 칼만 필터 예측 단계 (0) 2026.03.09 [칼만 필터는 어려워] 04. 칼만 필터 (0) 2026.03.07 [칼만 필터는 어려워] 03. 저주파 통과 필터 (0) 2026.03.06 [칼만 필터는 어려워] 02. 이동 평균 필터 (0) 2026.03.05