-
[칼만 필터는 어려워] 01. 평균 필터항법연구실/칼만필터 2026. 3. 4. 19:08
* 칼만필터는 어렵지 않아(지은이 김성필) 책을 보고 학습한 내용을 정리한 글입니다.
칼만필터를 이해하기 위한 첫걸음, 평균 필터에 대해 학습해보자.
칼만필터에 대한 좋은 정리글도 있지만 교재 찐득하게 보면서 하나씩 차근차근해야지
위성 궤도 결정을 주력으로 다루는 우리 랩실에서 칼만 필터를 다루는 이유는,
궤도 예측을 더 정확하게 하기 위함이다.
칼만 필터는 예측 모델과 센서 관측값 사이에서 최적의 균형을 찾아주는 알고리즘이다.
어떤 값에 가중치를 주고, 어떤 값은 덜어주는 균형을 맞춰나간다.
예측과 관측, 추정을 통해 측정치와 실제 값 사이의 차이를 줄여나간다.
아직 필터의 'ㅍ'도 모르는 필자이지만
칼만 필터를 이해하기 위해 재귀필터에 대해 알아보고자 글을 쓴다.
그리고 재귀 필터 중, 평균 필터에 대해 학습한다.
평균의 재귀식
평균의 정의에 따르면 새로운 값이 추가되었을 때, 모든 데이터를 다시 더한 후 데이터의 수(k)만큼 나누어주어야한다.
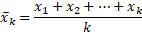
그러나 평균의 재귀식을 사용하면 간결한 필터로 표현이 가능하다.
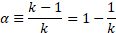
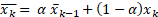
이 식의 형태를 평균 필터라고 부른다.
여기서 깊이 봐야할 정보는 \alpha 에 관한 것이다. k값이 클수록 \alpha 값도 커진다.
그럼 이 값이 뭘 의미하는가, 생각해보면 가중치라는 답이 나온다.
k값이 커진다는 것은 데이터의 수가 많아지는 것이고 .. 그럼 관측값이 많아진다고 생각할 수 있다.
그럼 관측값이 많이 쌓이면 쌓일수록 \alpha 값은 커지고 previous average에 곱해져 큰 가중치를 가져간다는 것을 알 수 있다.
반대로 입력받은 새로운 변수에 곱해지는 가중치는 작아진다.
예시로 다시 설명하겠지만, 데이터가 쌓여가면서 측정된 값에 포함된 노이즈는 희미해지고 점차 평균에 가까워지게 된다.
이러한 특성으로 식1.에 '필터'가 붙는다.
평균 필터 함수 - MATLAB 예시
function avg = AvgFilter(x) persistent preAvg k persistent Ini %function Reset if isempty(Ini) preAvg = 0; k = 0; Ini = 1; end alpha = (k-1)/k; avg = alpha*preAvg + (1-alpha)*x; preAvg = avg; k = k+1; endAvgFilter코드는 식1을 MATLAB코드로 작성한 것이다.
이 함수를 활용하여 main코드를 작성해보았다.
main코드의 알고리즘 또한 간단하다.
random으로 생성한 측정치를 가져오고 이 값을 평균의 재귀식, 필터 함수에 넣어 평균이 어떻게 변하는지를 보는 함수이다.
random값은 측정값은 평균에 14.4, 잡음(평균이 0이고 표준 편차가 4인 노이즈)을 더해 생성해주었다.
더보기* 평균이 0이고 표준편차가 4 ?
표준편차가 4라면 분산은 4의 제곱인 16이 된다. 그럼 해당 관측값의 오차는 16정도가 된다라는 것을 알 수 있다.
평균이 0이므로 한쪽으로 치우치는 편향(Bias)는 없지만, 변동 폭이 다소 크다.
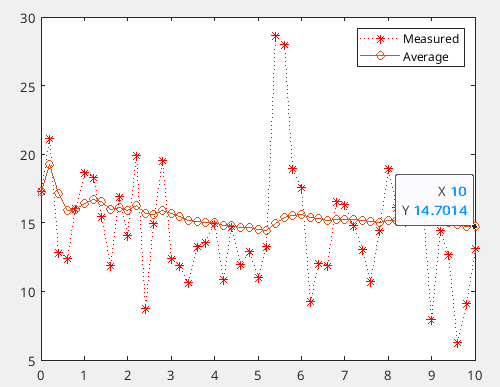
▐ k = 10일 때
▐ k = 20일 때

▐ k = 50일 때

▐ k = 100일 때

k값이 커질수록 평균의 흐름이 관측값에 영향을 덜 받는 것이 보인다.
특히 가중치 \alpha는 k가 커질수록 1에 가까워진다.
앞서 말했듯, 데이터가 쌓이면 쌓일수록 필터는 노이즈 하나로부터 받는 영향이 현저히 줄어든다.
측정값은 표준편차 4의 노이즈 때문에 계속 요동치지만, 평균은 0이므로 참값(약 14.4 근처)으로 수렴한다.
관측을 반복할수록 불확실성은 사라지고 참값에 가까워진다.
평균 필터는 데이터(k)가 많아질수록 측정 노이즈에 대한 변동성이 줄어들고
참값을 향해 수렴하는 직관적인 추정 도구이다.
불확실한 측정값 속에서 어떻게 최적의 상태를 추정할까? 라는 질문에 대한
답을 찾아가는 과정 첫번째를 배웠다. 평균 필터는 모든 데이터에 평등한 가중치를 주지만,
여기서 좀 더 발전시키면서 칼만 필터의 영역으로 들어가게 된다.
'항법연구실 > 칼만필터' 카테고리의 다른 글
[칼만 필터는 어려워] 06. 칼만 필터 예측 단계 (0) 2026.03.09 [칼만 필터는 어려워] 05. 칼만 필터 추정 단계 (0) 2026.03.09 [칼만 필터는 어려워] 04. 칼만 필터 (0) 2026.03.07 [칼만 필터는 어려워] 03. 저주파 통과 필터 (0) 2026.03.06 [칼만 필터는 어려워] 02. 이동 평균 필터 (0) 2026.03.05